本次内容的重点是BeanFactory 的创建、BeanDefinition 的构建以及配置文件的解析、还有Schema 机制分析(这里要结合dubbo 的一点点内容,对于dubbo 有一定了解的小伙伴可以看下,没有的话建议跳过,后面看dubbo 的时候在回来看这个内容)。
Spring源码下载 在源码分析之前,有一个前提就是你能看到源码,你得本地有源码。那么我们先说下怎么下载spring 的源码,这里和其余框架不同,目前spring 的源码下载后的项目依赖管理不是maven 而是Gradle。这里关于Gradle 的下载教程我就不细说了,网上有很多可以自己去找找,我这里重点要说的是通过GitHub 将spring 的源码下载下来之后,遇到的一些常见问题。对了这里还要下载git啊。
源码下载下来后,需要在bin目录下,执行 gradlew.bat(建议命令行中执行)。
需要在源码根目录下右击出Git Bash Here,点击后出现命令窗口(这个git下载了才会有)后用命令配置自己的GitHub 用户名、邮箱、密码等信息,具体命令我放在最后吧。这样能解决”process ‘command’ ‘git’ finishend with non-zero exit value“这样的报错。
还要注意Gradle 的版本不好是最新版本,我这边的版本是5.6.4版本,还有spring 中的gradle.properties 的文件,需要主要其中的版本version 信息需要保持一致。
最后一个就是如果使用idea 遇到了编码问题的话,可以在Help => Edit Custom VM Options,点击后再文件中添加“-Dfile.encoding=UTF-8”。
这样将代码导入基本上就没有什么问题,需要注意的是spring 目前要需要jdk 是jdk11 以上版本。注释版源码的话可以访问我的CSDN资源下载:源码
BeanFactory的创建 源码下载用idea加载后,我们可以先创建一个测试类,这个可以方便于我们后面debug。
1 2 3 4 5 6 7 8 9 public static void main (String[] args) { ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext ("classpath:applicationContext-cyclic.xml" ); TestService1 testService1 = (TestService1) applicationContext.getBean("testService1" ); TestService2 testService2 = (TestService2) applicationContext.getBean("testService2" ); testService1.aTest(); testService2.aTest(); }
那么现在我们就可以启动后直接跟进ClassPathXmlApplicationContext 的构建里面,这个可以跟到的第一个代码点。这里只需要继续跟进核心方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public ClassPathXmlApplicationContext ( String[] configLocations, boolean refresh, @Nullable ApplicationContext parent) throws BeansException { super (parent); setConfigLocations(configLocations); if (refresh) { refresh(); } }
下面这个方法内容过多,可以直接根据文章目录点击到prepareRefresh方法,下面这段代码后面会一点一点解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 public void refresh () throws BeansException, IllegalStateException { synchronized (this .startupShutdownMonitor) { prepareRefresh(); ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory(); prepareBeanFactory(beanFactory); try { postProcessBeanFactory(beanFactory); invokeBeanFactoryPostProcessors(beanFactory); registerBeanPostProcessors(beanFactory); initMessageSource(); initApplicationEventMulticaster(); onRefresh(); registerListeners(); finishBeanFactoryInitialization(beanFactory); finishRefresh(); } catch (BeansException ex) { if (logger.isWarnEnabled()) { logger.warn("Exception encountered during context initialization - " + "cancelling refresh attempt: " + ex); } destroyBeans(); cancelRefresh(ex); throw ex; } finally { resetCommonCaches(); } } }
进入核心方法,这里我们就需要一个一个方法看了,不过这次我们只看到BeanFactory 的创建和配置文件的解析。
prepareRefresh方法 首选我们可以看到的就是prepareRefresh 方法,这个方法其主要作用就是如下5点:
设置容器的启动时间
设置活跃状态为true
设置关闭状态为false
获取Environment对象,校验配置文件
准备监听器和事件的集合对象,默认为空的set集合
其实主要就是做一些准备工作,具体代码可以自己去翻一下,我这里就不看了。
obtainFreshBeanFactory-构建BeanFactory的方法 这方法是我们本次的重点,其主要做用也就是如下4点,这里我们需要一点点看。
1 2 3 4 5 6 7 8 ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
跟进该方法可以看到是主要调用refreshBeanFactory 和getBeanFactory 方法,这里的重点就是前者方法,后者只是将前者设置到的对象进行一个返回。
1 2 3 4 5 6 protected ConfigurableListableBeanFactory obtainFreshBeanFactory () { refreshBeanFactory(); return getBeanFactory(); }
过度方法-refreshBeanFactory方法等等 跟进后我们来到的是AbstractRefreshableApplicationContext 类中,目前方法第一步就是先判断BeanFactory 是否存在,因为容器中只能存在一个BeanFactory 对象,存在则销毁,然后在创建一个全新的BeanFactory 对象,然后设置一些默认属性,然后就是继续方法调用,最后返回创建好的对象,这里的重点又是下一步方法loadBeanDefinitions。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Override protected final void refreshBeanFactory () throws BeansException { if (hasBeanFactory()) { destroyBeans(); closeBeanFactory(); } try { DefaultListableBeanFactory beanFactory = createBeanFactory(); beanFactory.setSerializationId(getId()); customizeBeanFactory(beanFactory); loadBeanDefinitions(beanFactory); this .beanFactory = beanFactory; } catch (IOException ex) { throw new ApplicationContextException ("I/O error parsing bean definition source for " + getDisplayName(), ex); } }
因为我这里使用的xml 方式进行的配置,所以我进入的是AbstractXmlApplicationContext 类,如果是注解的话进入的就是AnnotationConfigWebApplicationContext 类。
这里基本工作就是获取一些资源解析器,用于后面的解析xml 配置信息,重点跟进的地方任然是loadBeanDefinitions 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Override protected void loadBeanDefinitions (DefaultListableBeanFactory beanFactory) throws BeansException, IOException { XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader (beanFactory); beanDefinitionReader.setEnvironment(this .getEnvironment()); beanDefinitionReader.setResourceLoader(this ); beanDefinitionReader.setEntityResolver(new ResourceEntityResolver (this )); initBeanDefinitionReader(beanDefinitionReader); loadBeanDefinitions(beanDefinitionReader); }
依然在AbstractXmlApplicationContext 类中,这里调用进入的方法都是同一个,只有获取资源的路径的方式不一样而已,还是需要跟进loadBeanDefinitions 方法,不过这次是AbstractBeanDefinitionReader 类中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 protected void loadBeanDefinitions (XmlBeanDefinitionReader reader) throws BeansException, IOException { Resource[] configResources = getConfigResources(); if (configResources != null ) { reader.loadBeanDefinitions(configResources); } String[] configLocations = getConfigLocations(); if (configLocations != null ) { reader.loadBeanDefinitions(configLocations); } }
继续看就是还是跟进,这里的作用就是一个计数,这里会根据不同的配置文件重复调用loadBeanDefinitions。
这里下一步还是AbstractBeanDefinitionReader 类的loadBeanDefinitions 重载方法,不过这里任然是调用loadBeanDefinitions 方法。
最后的我们达到的是XmlBeanDefinitionReader 类的loadBeanDefinitions 方法,然后紧接着是调用其doLoadBeanDefinitions 方法。
1 2 3 4 5 6 7 8 9 10 11 12 @Override public int loadBeanDefinitions (String... locations) throws BeanDefinitionStoreException { Assert.notNull(locations, "Location array must not be null" ); int count = 0 ; for (String location : locations) { count += loadBeanDefinitions(location); } return count; }
在这里我们会将xml 使用inputSource和resource加载,并封装成Document 对象。然后传入registerBeanDefinitions 方法,这里还有一堆的异常分析捕捉。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 protected int doLoadBeanDefinitions (InputSource inputSource, Resource resource) throws BeanDefinitionStoreException { try { Document doc = doLoadDocument(inputSource, resource); int count = registerBeanDefinitions(doc, resource); if (logger.isDebugEnabled()) { logger.debug("Loaded " + count + " bean definitions from " + resource); } return count; } catch (BeanDefinitionStoreException ex) { throw ex; } }
到了这里我们就已经快接近真正的解析了,我们可以直接看下面代码中的第3步BeanDefinitionDocumentReader 对象的registerBeanDefinitions 方法调用。
1 2 3 4 5 6 7 8 9 10 public int registerBeanDefinitions (Document doc, Resource resource) throws BeanDefinitionStoreException { BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader(); int countBefore = getRegistry().getBeanDefinitionCount(); documentReader.registerBeanDefinitions(doc, createReaderContext(resource)); return getRegistry().getBeanDefinitionCount() - countBefore; }
进入后就是doRegisterBeanDefinitions 方法的调用。这里我们依旧是看重点parseBeanDefinitions 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 protected void doRegisterBeanDefinitions (Element root) { BeanDefinitionParserDelegate parent = this .delegate; this .delegate = createDelegate(getReaderContext(), root, parent); if (this .delegate.isDefaultNamespace(root)) { String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE); if (StringUtils.hasText(profileSpec)) { } } } preProcessXml(root); parseBeanDefinitions(root, this .delegate); postProcessXml(root); this .delegate = parent; }
总结一下上面的过度方法:就是将原本的配置信息,转换封装为方便解读的对象,然后准备初始化一系类的解析器,并对返回对象进行封装等等。这里也看出xml 配置和注解配置,也就是这里会有一定的区别。
解析配置信息-parseBeanDefinitions方法 继续到了这一步,我们就算到了真正解析xml配置文件的地方了,这里还会涉及到后面的Schema 机制分析。
这里一共是两种解析方式:parseDefaultElement 默认命名空间默认节点的处理,比如常规的bean 标签等等、parseCustomElement 自定义命名空间自定义节点的处理,比如dubbo 提供的dubbo:service 标签等或者我们自定的标签,还有就是spring 本身的一些标签比如aop 标签等,这里其实也就是Schema 机制的解析方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 protected void parseBeanDefinitions (Element root, BeanDefinitionParserDelegate delegate) { if (delegate.isDefaultNamespace(root)) { NodeList nl = root.getChildNodes(); for (int i = 0 ; i < nl.getLength(); i++) { Node node = nl.item(i); if (node instanceof Element) { Element ele = (Element) node; if (delegate.isDefaultNamespace(ele)) { parseDefaultElement(ele, delegate); } else { delegate.parseCustomElement(ele); } } } } else { delegate.parseCustomElement(root); } }
默认命名空间的解析方式-parseDefaultElement 我们就先看parseDefaultElement 的解析方式,首选是对各种默认标签进行分类处理,我们只看bean 标签的处理方式就好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private void parseDefaultElement (Element ele, BeanDefinitionParserDelegate delegate) { if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) { importBeanDefinitionResource(ele); } else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) { processAliasRegistration(ele); } else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) { processBeanDefinition(ele, delegate); } else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) { doRegisterBeanDefinitions(ele); } }
Bean标签的解析方法-processBeanDefinition 这里首先就是通过parseBeanDefinitionElement 方法解析标签中的所有内容,然后构建出BeanDefinition 这个对象,这个对象中存储的就是具体的配置信息,比如bean 的id、name、class 等属性,代码中虽然是BeanDefinitionHolder 但是它本身也就是对BeanDefinition 的一个封装而已。这里具体的解析标签的方法就详细看了,因为大部分跟市面上的解析方式都差不多,MyBatis 好像也就是一个套路。
这里的第二个重点就是registerBeanDefinition 注册方法,这个说直白一点就是为DefaultListableBeanFactory 对象,也就是往上面创建的BeanFactory 对象的beanDefinitionMap 集合添加对应的BeanDefinition 值,注意的是BeanDefinition 是一个ConcurrentHashMap 集合,并且这里是私有常量。
到这里Bean 的解析工作就算是结束了,同时也验证了上篇文章所有的是先创建了BeanFactory 对象,然后再解析构建的BeanDefinition 对象,最后又将BeanDefinition 对象存入了BeanFactory 对象中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 protected void processBeanDefinition (Element ele, BeanDefinitionParserDelegate delegate) { BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele); if (bdHolder != null ) { bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder); try { BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry()); } catch (BeanDefinitionStoreException ex) { getReaderContext().error("Failed to register bean definition with name '" + bdHolder.getBeanName() + "'" , ele, ex); } getReaderContext().fireComponentRegistered(new BeanComponentDefinition (bdHolder)); } }
Schema 机制分析 结合上面的解析配置信息的内容,我们在这里简单的说一下Schema 机制,这里需要用到dubbo 的一点知识。
下面就是dubbo 的常用配置xml,结合刚刚上面的内容,spring 启动的时候是只能解析下面的配置的bean 标签,对于dubbo 标签是没有解析的,但是上面内容也提到自义定命名空间和标签,也是可以通过parseCustomElement 方法来进行解析的,而这段解析内容也可以算是schema 机制的重点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <?xml version="1.0" encoding="UTF-8" ?> <beans xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xmlns:dubbo ="http://dubbo.apache.org/schema/dubbo" xmlns ="http://www.springframework.org/schema/beans" xsi:schemaLocation ="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd" > <dubbo:application name ="demo-provider" /> <dubbo:registry address ="zookeeper://127.0.0.1:2181" /> <dubbo:protocol name ="dubbo" /> <bean id ="demoService" class ="org.apache.dubbo.demo.provider.DemoServiceImpl" /> <dubbo:service interface ="org.apache.dubbo.demo.DemoService" ref ="demoService" /> <bean id ="myDemoService" class ="org.apache.dubbo.demo.provider.MyDemoServiceImpl" /> <dubbo:service interface ="org.apache.dubbo.demo.MyDemoService" ref ="myDemoService" /> </beans >
自定义命名空间和标签 我们先要了解的是怎样才算是自定义命名空间,其实我们将上面的xml 配置和spring 常规xml 配置对比,就能发现beans 标签中多了一个xmlns:dubbo 的属性,而xsi:schemaLocation 属性中也多出了一段关于dubbo 的dubbo.xsd 配置。
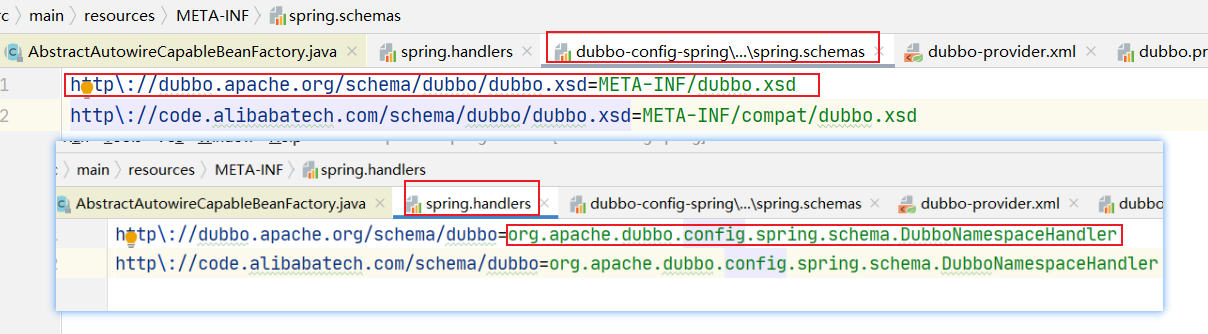
这两个东西具体作用就是:dubbo.xsd 文件规定了dubbo 标签的语法;而http://dubbo.apache.org/schema/dubbo 对应着META-INF 目录下spring.handlers 文件中配置的解析器类的路径。dubbo.xsd 文件也是在这个目录下的spring.schemas 文件导向的。
自定义命名空间和标签的解析-parseCustomElement方法 既然知道了相关的语法和对象的解析器,那么我们就可以回到parseCustomElement 方法看看具体的解析内容,直接可以定位到BeanDefinitionParserDelegate 类的parseCustomElement 方法。
我们这里重点看两个地方,其一是:得到一个命名空间处理器,也就是resolve 方法、其二就是:开始解析,也就是parse 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Nullable public BeanDefinition parseCustomElement (Element ele, @Nullable BeanDefinition containingBd) { String namespaceUri = getNamespaceURI(ele); if (namespaceUri == null ) { return null ; } NamespaceHandler handler = this .readerContext.getNamespaceHandlerResolver().resolve(namespaceUri); if (handler == null ) { error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]" , ele); return null ; } return handler.parse(ele, new ParserContext (this .readerContext, this , containingBd)); }
先看resolve 方法,这里我们其实要看的就是三个部分,初始化、缓存、返回,重点就是初始化。
这里可能还有人有疑惑,到底是怎么得到解析器的,其实就是spring 中的约定,约定好schema 就是通过spring.handlers 文件得到解析器,spring.schemas 文件规定语法,然后spring 项目中全部这个命名的文件内容,然后将信息存储下来。
既然我们上面已经得到了整个dubbo 的xml 配置文件,那么也就是得到了先关的beans 标签的值,这里就可以通过http://dubbo.apache.org/schema/dubbo 获取到相关的解析器,也就是DubboNamespaceHandler 对象,这个对象的顶层父类也就是NamespaceHandler 对象。
1 2 3 4 NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);namespaceHandler.init(); handlerMappings.put(namespaceUri, namespaceHandler); return namespaceHandler;
然后就是DubboNamespaceHandler 对象的init 初始化方法。这里的初始化写法是固定的,又spring 提供,这可以看到是将各个不同标签的解析对象都创建,并封装成了DubboBeanDefinitionParser 对象,那么后面调用的话只是调用了DubboBeanDefinitionParser 对象的parse 方法,而不是对应的解析器的parse 方法,比如service 标签对应的ServiceBean 解析器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Override public void init () { registerBeanDefinitionParser("application" , new DubboBeanDefinitionParser (ApplicationConfig.class, true )); registerBeanDefinitionParser("module" , new DubboBeanDefinitionParser (ModuleConfig.class, true )); registerBeanDefinitionParser("registry" , new DubboBeanDefinitionParser (RegistryConfig.class, true )); registerBeanDefinitionParser("config-center" , new DubboBeanDefinitionParser (ConfigCenterBean.class, true )); registerBeanDefinitionParser("metadata-report" , new DubboBeanDefinitionParser (MetadataReportConfig.class, true )); registerBeanDefinitionParser("monitor" , new DubboBeanDefinitionParser (MonitorConfig.class, true )); registerBeanDefinitionParser("metrics" , new DubboBeanDefinitionParser (MetricsConfig.class, true )); registerBeanDefinitionParser("provider" , new DubboBeanDefinitionParser (ProviderConfig.class, true )); registerBeanDefinitionParser("consumer" , new DubboBeanDefinitionParser (ConsumerConfig.class, true )); registerBeanDefinitionParser("protocol" , new DubboBeanDefinitionParser (ProtocolConfig.class, true )); registerBeanDefinitionParser("service" , new DubboBeanDefinitionParser (ServiceBean.class, true )); registerBeanDefinitionParser("reference" , new DubboBeanDefinitionParser (ReferenceBean.class, false )); registerBeanDefinitionParser("annotation" , new AnnotationBeanDefinitionParser ()); }
DubboBeanDefinitionParser 对象的parse 方法的调用,这里则是通过不同的标签来构建出真正的解析器,比如service 标签对应的ServiceBean 解析器。
而解析器的真正调用,也就是真正的标签解析,我们后面说。这里解析器逻辑只针对dubbo 啊,其余的不同框架都有一定的差异,但是大体流程就是这样的。
总结 本次的内容的重点就是BeanFactory 的创建流程、BeanDefinition 的构建和存储、缓存,配置信息的解析。结合之前的流程图,这也是完成对象实例化和初始化之前的准备工作,目前BeanFactory 的单例池是没有任何配置对象的,添加对象那是后面的事情。下一篇就是BeanFactoryPostProcessor 和BeanPostProcessor 的区别了。
附录Spring 源码分析系列文章 IOC
AOP